

Why do we use n-1 instead of n in statistics?
Understanding Bessel's correction



If you have ever calculated the sample variance or the sample standard deviation from a set of data, you might have noticed that the formulas involve dividing by n-1 instead of n, where n is the number of observations in the sample. This adjustment is called Bessel’s correction, and it is used to correct the bias in the estimation of the population variance and standard deviation. But what does this mean, and why do we need to do it?
What is bias?
Bias is a measure of how far an estimator (a formula or a method that we use to estimate a parameter) is from the true value of the parameter. For example, if we want to estimate the average height of all people in the world, we can use the sample mean (the average height of a sample of people) as an estimator. However, this estimator might not be exactly equal to the population mean (the average height of the entire population), because our sample might not be representative of the whole population. The difference between the sample mean and the population mean is called the bias of the estimator.
Ideally, we want our estimators to be unbiased, which means that their expected value (the average value that we would get if we repeated the estimation many times with different samples) is equal to the true value of the parameter. An unbiased estimator gives us an accurate estimate of the parameter on average.
Why is the sample variance biased?
The sample variance is one of the most common estimators that we use in statistics. It measures how spread out the data values are around the sample mean. The formula for the sample variance is:
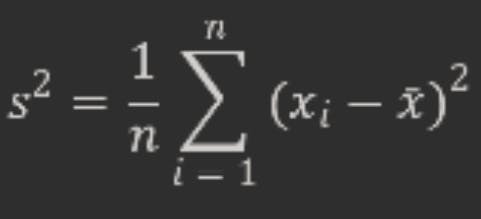
where xi are the data values, ˉxˉ is the sample mean, and n is the sample size.
However, this formula does not give us an unbiased estimator of the population variance, which is:
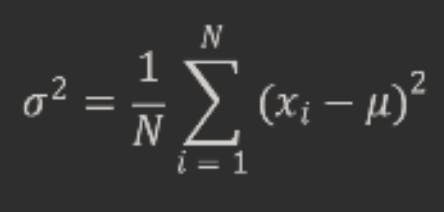
where xi are the population values, μ is the population mean, and N is the population size.
The reason why the sample variance is biased is that we are using the sample mean instead of the population mean in the formula. The sample mean is closer to the data values than the population mean, which means that the deviations (xi − ˉxˉ) are smaller than the deviations (xi−μ). This leads to a smaller sum of squares and a smaller sample variance. In other words, using the sample mean deflates the variability in the data.
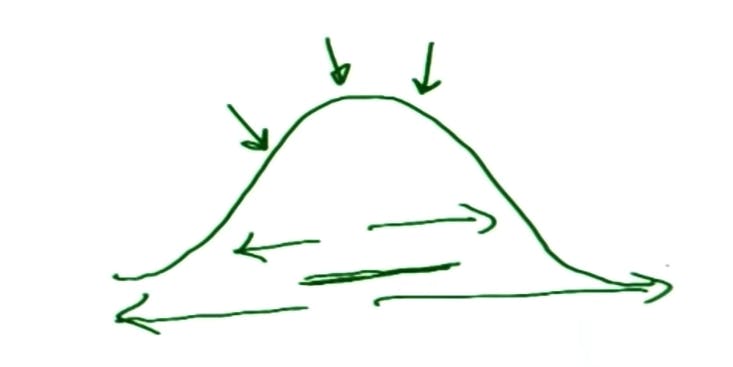
In very simple language, a sample is more likely to come from the more probable values of the population (as shown in the diagram below) and hence reduces the overall deviation from the mean.
How does Bessel’s correction fix this?
Bessel’s correction is a simple way to reduce the bias in the sample variance. It involves multiplying the sum of squares by a factor of n/(n-1), which is equivalent to dividing by n−1 instead of n in the formula. The corrected formula for the sample variance is:
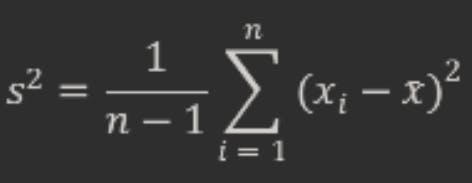
This correction increases the sample variance and makes it closer to the population variance on average. The intuition behind this correction is that we are losing one degree of freedom when we use the sample mean instead of the population mean. A degree of freedom is a measure of how much information we have in our data. When we use the sample mean, we are using one piece of information from our data to estimate another parameter (the population mean), which reduces our degrees of freedom by one. Therefore, we divide by n−1 instead of n to account for this loss.
Bessel’s correction also applies to other estimators that involve using the sample mean, such as the sample standard deviation, which is defined as:
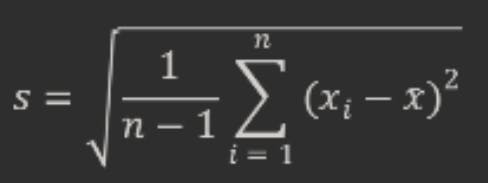
However, Bessel’s correction does not make these estimators unbiased. The sample standard deviation is still a biased estimator of the population standard deviation, because taking the square root introduces another source of bias. However, Bessel’s correction reduces this bias and makes it smaller than without it.
When should we use Bessel’s correction?
Bessel’s correction is only necessary when we are estimating a parameter from a sample and we do not know its true value in the population. For example, if we know that our data comes from a normal distribution with a known mean and variance, then we do not need to use Bessel’s correction when calculating the sample variance or standard deviation. However, in most cases, we do not know the population parameters and we have to estimate them from the sample. In that case, Bessel’s correction helps us to get more accurate estimates.
However, Bessel’s correction is not a perfect solution. It does not guarantee that our estimators will be unbiased or have the minimum mean squared error (MSE), which is another measure of how good an estimator is. The MSE is the average of the squared differences between the estimator and the true value of the parameter. An estimator with a smaller MSE is more precise and has less variability. Bessel’s correction often increases the MSE of the sample variance and standard deviation, because it increases their variability more than it reduces their bias. Furthermore, there is no population distribution for which Bessel’s correction gives the minimum MSE, because a different scale factor can always be chosen to minimize MSE.
Therefore, Bessel’s correction is a trade-off between bias and variability. It is a simple and convenient way to reduce the bias in the sample variance and standard deviation, but it comes at the cost of increasing their variability and MSE. Whether we use Bessel’s correction or not depends on our goals and preferences. If we want to minimize bias, then we should use Bessel’s correction. If we want to minimize MSE, then we should use a different correction or no correction at all.